1.Rete 算法
:
Rete 在拉丁语中是 ”net” ,有网络的意思。 RETE 算法可以分为两部分:规则编译( rule compilation )和运行时执行( runtime execution )。
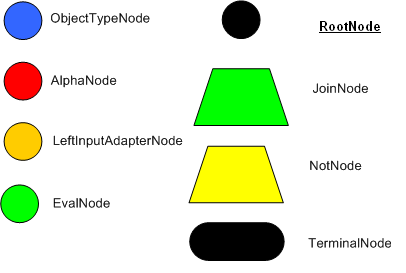
编译算法描述了规则如何在 Production Memory 中产生一个有效的辨别网络。用一个非技术性的词来说,一个辨别网络就是用来过滤数据。方法是通过数据在网络中的传播来过滤数据。在顶端节点将会有很多匹配的数据。当我们顺着网络向下走,匹配的数据将会越来越少。在网络的最底部是终端节点( terminal nodes )。在 Dr Forgy 的 1982 年的论文中,他描述了 4 种基本节点: root , 1-input, 2-input and terminal 。下图是 Drools 中的 RETE
节点类型:
Figure 1. Rete Nodes
根节点( RootNode )是所有的对象进入网络的入口。然后,从根节点立即进入到 ObjectTypeNode 。 ObjectTypeNode 的作用是使引擎只做它需要做的事情。例如,我们有两个对象集: Account 和 Order 。如果规则引擎需要对每个对象都进行一个周期的评估,那会浪费很多的时间。为了提高效率,引擎将只让匹配 object type 的对象通过到达节点。通过这种方法,如果一个应用 assert 一个新的 account ,它不会将 Order 对象传递到节点中。很多现代
RETE 实现都有专门的 ObjectTypeNode 。在一些情况下, ObjectTypeNode 被用散列法进一步优化。
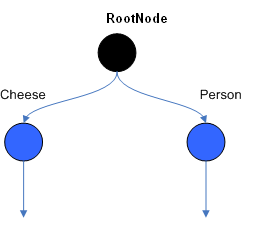
Figure 2 . ObjectTypeNodes
ObjectTypeNode 能够传播到 AlphaNodes, LeftInputAdapterNodes 和 BetaNodes 。
1-input 节点通常被称为 AlphaNode 。 AlphaNodes 被用来评估字面条件( literal conditions )。虽然, 1982 年的论文只提到了相等条件(指的字面上相等),很多 RETE 实现支持其他的操作。例如, Account.name = = “Mr Trout” 是一个字面条件。当一条规则对于一种 object type 有多条的字面条件,这些字面条件将被链接在一起。这是说,如果一个应用 assert 一个 account 对象,在它能到达下一个 AlphaNode
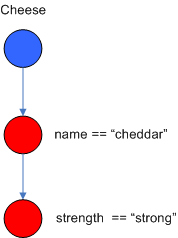
之前,它必须先满足第一个字面条件。在 Dr. Forgy 的论文中,他用 IntraElement conditions 来表述。下面的图说明了 Cheese 的 AlphaNode 组合( name = = “cheddar” , strength = = “strong” ):
Figure 3. AlphaNodes
Drools 通过散列法优化了从 ObjectTypeNode 到 AlphaNode 的传播。每次一个 AlphaNode 被加到一个 ObjectTypeNode 的时候,就以字面值( literal value )作为 key ,以 AlphaNode 作为 value 加入 HashMap 。当一个新的实例进入 ObjectTypeNode 的时候,不用传递到每一个 AlphaNode ,它可以直接从 HashMap 中获得正确的 AlphaNode ,避免了不必要的字面检查。
<!--[if !supportEmptyParas]-->
2-input 节点通常被称为 BetaNode 。 Drools 中有两种 BetaNode : JoinNode 和 NotNode 。 BetaNodes 被用来对 2 个对象进行对比。这两个对象可以是同种类型,也可以是不同类型。
我们约定 BetaNodes 的 2 个输入称为左边( left )和右边( right )。一个 BetaNode 的左边输入通常是 a list of objects 。在 Drools 中,这是一个数组。右边输入是 a single object 。两个 NotNode 可以完成‘ exists ’检查。 Drools 通过将索引应用在 BetaNodes 上扩展了 RETE 算法。下图展示了一个 JoinNode 的使用:
Figure 4 . JoinNode
注意到图中的左边输入用到了一个 LeftInputAdapterNode ,这个节点的作用是将一个 single Object 转化为一个单对象数组( single Object Tuple ),传播到 JoinNode 节点。因为我们上面提到过左边输入通常是 a list of objects 。
<!--[if !supportEmptyParas]-->
Terminal nodes 被用来表明一条规则已经匹配了它的所有条件( conditions )。 在这点,我们说这条规则有了一个完全匹配( full match )。在一些情况下,一条带有“或”条件的规则可以有超过一个的 terminal node 。
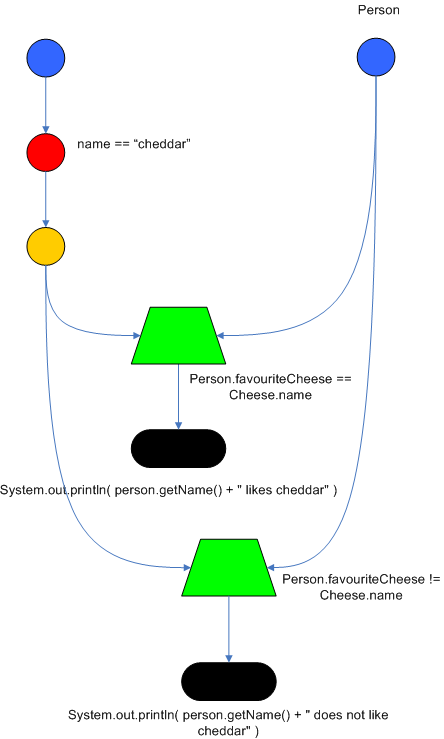
Drools 通过节点的共享来提高规则引擎的性能。因为很多的规则可能存在部分相同的模式,节点的共享允许我们对内存中的节点数量进行压缩,以提供遍历节点的过程。下面的两个规则就共享了部分节点:
这里我们先不探讨这两条 rule 到的是什么意思,单从一个直观的感觉,这两条 rule 在它们的 LHS 中基本都是一样的,只是最后的
favouriteCheese ,一条规则是等于 $cheddar ,而另一条规则是不等于
$cheddar 。下面是这两条规则的节点图:
Figure 5 . Node Sharing
从图上可以看到,编译后的 RETE 网络中, AlphaNode 是共享的,而 BetaNode 不是共享的。上面说的相等和不相等就体现在 BetaNode 的不同。然后这两条规则有各自的 Terminal Node 。
<!--[if !supportEmptyParas]-->
2. Leaps 算法:
Production systems 的 Leaps 算法使用了一种“ lazy ”方法来评估条件( conditions )。一种 Leaps 算法的修改版本的实现,作为 Drools v3 的一部分,尝试结合 Leaps 和 RETE 方法的最好的特点来处理 Working Memory 中的 facts 。
古典的 Leaps 方法将所有的 asserted 的 facts ,按照其被 asserted 在 Working Memory 中的顺序( FIFO ),放在主堆栈中。它一个个的检查 facts ,通过迭代匹配 data type 的 facts 集合来找出每一个相关规则的匹配。当一个匹配的数据被发现时,系统记住此时的迭代位置以备待会的继续迭代,并且激发规则结果( consequence )。当结果( consequence )执行完成以后,系统就会继续处理处于主堆栈顶部的 fact 。如此反复。
rule
when
Cheese( $chedddar : name ==
" cheddar "
)
$person : Person( favouriteCheese !=
$cheddar )
then
System.out.println( $person.getName() +
" does likes cheddar
" );
end
rule
when
Cheese( $chedddar : name ==
" cheddar "
)
$person : Person( favouriteCheese ==
$cheddar )
then
System.out.println( $person.getName() +
" likes cheddar
" );
end
分享到:





相关推荐
drools-rete算法简介.docx
改进Rete算法对电信计费规则引擎系统性能的提升,钟小安,,本文详细描述了改进电信计费系统中规则引擎组件Rete算法的两种实现方式-在Alpha存储区对Alpha节点进行哈希查找和在Beta存储区对Beta节点�
URULE是一款基于RETE算法的纯Java规则引擎,提供规则集、决策表、决策树、评分卡,规则流等各种规则表现工具及基于网页的可视化设计器,可快速开发出各种复杂业务规则。
从老外网站那里下载的最好的描述rete算法的ppt
Charles L. Forgy的rete文章
在此理论基础上,将一种高效的模式匹配算法——Rete算法引入到实际的故障的诊断系统中,以保证故障诊断的高效性和准确性。为此在实际系统中,借助规则引擎将故障信息规则化,并将故障诊断流程以层次分明的XML文档...
行业分类-设备装置-一种结合Rete算法的RDF数据分布式并行推理方法
基于RETE算法的纯Java规则引擎,提供规则集、决策表、决策树、评分卡,规则流等各种规则表现工具及
生锈的网 Rete 算法在 Rust 中的实现。
URule是一款纯Java规则引擎,它以RETE算法为基础,提供了向导式规则集、脚本式规则集、决策表、交叉决策表(PRO版提供)、决策树、评分卡及决策流共六种类型的规则定义方式,配合基于WEB的设计器,可快速实现规则的...
#资源达人分享计划#
针对传统的规则引擎算法――Rete算法会缓存大量的部分匹配结果,而RFID事件通常具有时间约束的特点,提出一种基于部分匹配过期的过期数据回收机制,及时删除过期的部分匹配结果,减小计算过程中缓存的压力。...
提供规则集、决策表、决策树、评分卡,规则流等各种规则表现工具及基于网页的可视化设计器,可快速开发出各种复杂业务规则。 开发工具在软件开发生命周期中扮演着至关重要的角色,它们旨在简化和加速从概念设计到...
Improved rete算法, 基于规则的专家系统采用的快速算法
动态演化系统中规则引擎的改进Rete算法
Treat 算法论文原文 英文 treat 算法 rete算法相关 This paper presents the TREAT match algorithm for AI production systems. The TREAT algorithm introduces a new method of state saving in production ...