ن¸ٹن¸€ç¯‡هچڑه®¢ï¼Œن»‹ç»چن؛†Linux وٹ“هڈ–网é،µçڑ„ه®ن¾‹ï¼Œه…¶ن¸هœ¨وٹ“هڈ–google playه›½ه¤–网é،µو—¶ï¼Œéœ€è¦پ用هˆ°ن»£çگ†وœچهٹ،ه™¨
ن»£çگ†çڑ„用途
ه…¶ه®ï¼Œé™¤ن؛†وٹ“هڈ–ه›½ه¤–网é،µéœ€è¦پ用هˆ°IPن»£çگ†ه¤–,è؟کوœ‰ه¾ˆه¤ڑهœ؛و™¯ن¼ڑ用هˆ°ن»£çگ†ï¼ڑ
- é€ڑè؟‡ن»£çگ†è®؟é—®ن¸€ن؛›ه›½ه¤–网站,绕è؟‡è¢«وںگه›½éک²çپ«ه¢™è؟‡و»¤وژ‰çڑ„网站
- ن½؟用و•™è‚²ç½‘çڑ„ن»£çگ†وœچهٹ،ه™¨ï¼Œهڈ¯ن»¥è®؟é—®هˆ°ه¤§ه¦وˆ–ç§‘ç ”é™¢و‰€çڑ„ه†…部网站资و؛گ
- هˆ©ç”¨è®¾ç½®ن»£çگ†ï¼Œوٹٹ请و±‚é€ڑè؟‡ن»£çگ†وœچهٹ،ه™¨ن¸‹è½½ç¼“هکهگژ,ه†چن¼ ه›وœ¬هœ°ï¼Œوڈگé«کè®؟é—®é€ںه؛¦
- 黑ه®¢هڈ‘هٹ¨و”»ه‡»و—¶ï¼Œهڈ¯ن»¥é€ڑè؟‡ن½؟用ه¤ڑé‡چن»£çگ†و¥éڑگè—ڈوœ¬وœ؛çڑ„IPهœ°ه€ï¼Œéپ؟ه…چ被è·ںè¸ھ(ه½“然,é”é«کن¸€ه°؛,éپ“é«کن¸€ن¸ˆï¼Œç»ˆç©¶ن¼ڑ被traced)
ن»£çگ†çڑ„هژںçگ†
ن»£çگ†وœچهٹ،çڑ„هژںçگ†وک¯وœ¬هœ°وµڈ览ه™¨ï¼ˆBrowser)هڈ‘é€پ请و±‚çڑ„و•°وچ®ï¼Œن¸چوک¯ç›´وژ¥هڈ‘é€پ给网站وœچهٹ،ه™¨ï¼ˆWeb Server)
而وک¯é€ڑè؟‡ن¸é—´çڑ„ن»£çگ†وœچهٹ،ه™¨ï¼ˆProxy)و¥ن»£و›؟ه®Œوˆگ,ه¦‚ن¸‹ه›¾ï¼ڑ
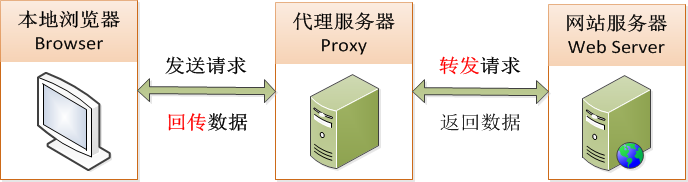
IPن»£çگ†ç›é€‰ç³»ç»ں
é—®é¢کهˆ†وگ
- ه› ن¸؛ن¸چهڈ¯èƒ½و¯ڈه¤©éƒ½éپچهژ†وµ‹è¯•ه…¨çگƒ2^32و•°é‡ڈç؛§çڑ„IPهœ°ه€ï¼Œو¥çœ‹ه“ھن¸ھIPهڈ¯ç”¨ï¼Œه› و¤é¦–è¦په·¥ن½œه°±وک¯ه¯»و‰¾ه¾…选çڑ„ن»£çگ†IPو؛گï¼ں
- هˆو¥ç،®ه®ڑن؛†ه¾…选ن»£çگ†IPو؛گ,ه¦‚ن½•ç،®ه®ڑè؟™é‡Œé¢çڑ„و¯ڈن¸€ن¸ھIPوک¯çœںçڑ„هڈ¯ç”¨ï¼ں
- ه¯»و‰¾هˆ°çڑ„ه¾…选ن»£çگ†IPو؛گ,وک¯ن»¥ن»€ن¹ˆو ¼ه¼ڈن؟هکçڑ„ï¼ں需è¦پè؟›è،Œو–‡وœ¬é¢„ه¤„çگ†هگ—ï¼ں
- 选و‹©ه¹¶ç،®ه®ڑن؛†وںگن¸ھن»£çگ†IPهڈ¯ç”¨ï¼Œن½†هœ¨ن¸‹è½½ç½‘é،µè؟‡ç¨‹ن¸هڈ¯èƒ½ن¼ڑهڈˆçھپ然ه¤±و•ˆن؛†ï¼Œه¦‚ن½•ç»§ç»وٹ“هڈ–ه‰©ن¸‹çڑ„网é،µï¼ں
- ه¦‚وœé‡چو–°é€‰و‹©ن؛†ن¸€ن¸ھهڈ¯ç”¨çڑ„ن»£çگ†IPه®Œوˆگن؛†ه‰©ن¸‹çڑ„网é،µوٹ“هڈ–,ن¸؛ن؛†و–¹ن¾؟ن¸‹و¬،ن½؟用,需è¦په°†ه®ƒو›´و–°هˆ°12ه›½وٹ“هڈ–è„ڑوœ¬ن¸ï¼Œè¯¥ه¦‚ن½•ه®çژ°ه‘¢ï¼ں
- ن¸ٹ篇هچڑه®¢ن¸وڈگهˆ°è؟‡ï¼Œهœ¨وٹ“هڈ–و¸¸وˆڈوژ’هگچ网é،µه’Œو¸¸وˆڈ网é،µçڑ„è؟‡ç¨‹ن¸ï¼Œéƒ½éœ€è¦پن½؟用ن»£çگ†IPو¥ن¸‹è½½ç½‘é،µï¼Œه¦‚وœéپ‡هˆ°ن¸ٹé¢çڑ„ن»£çگ†IPçھپ然ه¤±و•ˆï¼Œè¯¥ه¦‚ن½•è§£ه†³ï¼ں
- ه¦‚وœن¸€ن¸ھن»£çگ†IPه¹¶و²،وœ‰ه¤±و•ˆï¼Œن½†وک¯ه®ƒوٹ“هڈ–网é،µçڑ„é€ںه؛¦ه¾ˆو…¢وˆ–وپو…¢ï¼Œ24ه°ڈو—¶ه†…و— و³•ه®Œوˆگه¯¹ه؛”ه›½ه®¶çڑ„网é،µوٹ“هڈ–ن»»هٹ،,该و€ژن¹ˆهٹï¼ں需è¦پé‡چو–°ç›é€‰ن¸€ن¸ھو›´ه؟«çڑ„هگ—ï¼ں
- ه¦‚وœوٹٹو‰€وœ‰ن»£çگ†IPو؛گç›é€‰ن¸€éپچهگژ,ن»چ然و²،وœ‰ن¸€ن¸ھهڈ¯ç”¨çڑ„ن»£çگ†IP,该و€ژن¹ˆهٹï¼ںوک¯ç»§ç»ه¾ھçژ¯ه†چç›é€‰ن¸€و¬،وˆ–ه¤ڑو¬،,è؟کوک¯ه¯»و‰¾و–°çڑ„ن»£çگ†IPو؛گï¼ں
هˆ†وگ解ه†³ن¸€ن¸ھه®é™…é—®é¢کو—¶ï¼Œه°†ن¼ڑéپ‡هˆ°هگ„ç§چé—®é¢ک,وœ‰ن؛›é—®é¢کç”ڑ至وک¯و–¹و،ˆè®¾è®،ن¹‹هˆéƒ½éڑ¾ن»¥وƒ³هˆ°çڑ„(ه¦‚ن»£çگ†IPوٹ“هڈ–网é،µé€ںه؛¦è؟‡و…¢ï¼‰ï¼Œوˆ‘çڑ„ن½“ن¼ڑوک¯ï¼ڑهٹ¨و‰‹ه®è·µو¯”ç؛¯çگ†è®؛و›´é‡چè¦پï¼پ
و–¹و،ˆè®¾è®،
و€»ن½“و€è·¯ï¼ڑه¯»و‰¾ه¹¶ç¼©ه°ڈç›é€‰çڑ„IPن»£çگ†و؛گ——م€‹و£€وµ‹ن»£çگ†IPوک¯هگ¦هڈ¯ç”¨â€”—م€‹IPهڈ¯ç”¨هˆ™è®°ه½•ن¸‹و¥وٹ“هڈ–网é،µâ€”—م€‹ن»£çگ†IPو•…éڑœهˆ™é‡چو–°ç›é€‰â€”—م€‹ç»§ç»وٹ“هڈ–网é،µâ€”—م€‹ه®Œوˆگ

1م€پIPن»£çگ†و؛گ
选و‹©وœ‰ن¸¤ن¸ھهژںهˆ™ï¼ڑهڈ¯ç”¨ه’Œه…چ费,ç»ڈè؟‡و·±ه…¥è°ƒç ”ه’Œوگœç´¢ï¼Œوœ€هگژç،®ه®ڑن¸¤ن¸ھ网站çڑ„IPن»£çگ†و¯”较é è°±ï¼ڑfreeproxylists.netه’Œxroxy.com
ن»ژه›½ه®¶و•°م€پIPن»£çگ†و•°é‡ڈم€پIPن»£çگ†هڈ¯ç”¨çژ‡م€پIPن»£çگ†و–‡وœ¬و ¼ه¼ڈç‰ه¤ڑو–¹é¢ç»¼هگˆè€ƒé‡ڈ,IPن»£çگ†و؛گن¸»è¦پ选è‡ھه‰چ者,هگژ者ن½œن¸؛è،¥ه……,هœ¨هگژو¥çڑ„ه®è·µوµ‹è¯•è،¨وکژè؟™ç§چهˆé€‰و–¹و،ˆهں؛وœ¬و»،足需و±‚
2م€پو–‡وœ¬é¢„ه¤„çگ†
ن»ژfreeproxylists.netèژ·هڈ–çڑ„ن»£çگ†IP,وœ‰IPهœ°ه€م€پ端هڈ£م€پç±»ه‹م€پهŒ؟هگچو€§م€په›½ه®¶...ç‰ç‰هڈ‚و•°ï¼Œè€Œوˆ‘ن»¬éœ€è¦پçڑ„ن»…ن»…وک¯IP+Port,ه› و¤éœ€è¦په¯¹هˆé€‰çڑ„IPن»£çگ†و؛گهپڑو–‡وœ¬é¢„ه¤„çگ†
و–‡وœ¬ç©؛و ¼ه¤„çگ†ه‘½ن»¤ï¼ڑ
sed -e "s/\s\{2,\}/:/g" $file_input > $file_split
sed -i "s/ /:/g" $file_split
هگˆه¹¶ن»£çگ†IP(ip:port)ه‘½ن»¤ï¼ڑ
proxy_ip=$(echo $line | cut -f 1 -d ":")
proxy_port=$(echo $line | cut -f 2 -d ":")
proxy=$proxy_ip":"$proxy_port
3م€پو£€وµ‹IPن»£çگ†
و–‡وœ¬é¢„ه¤„çگ†ن»£çگ†IPن¸؛و ‡ه‡†و ¼ه¼ڈ(ip:port)هگژ,需è¦پè؟›è،Œن»£çگ†IPç›é€‰وµ‹è¯•ï¼Œçœ‹ه“ھن؛›هڈ¯ç”¨ه“ھن؛›ن¸چهڈ¯ç”¨ï¼ˆç”±ن؛ژèژ·هڈ–çڑ„IPن»£çگ†و؛گوœ‰ن¸€ن؛›ن¸چ能ن½؟用وˆ–ن¸‹è½½è؟‡و…¢ï¼Œéœ€è¦پè؟‡و»¤وژ‰ï¼‰
curlوٹ“هڈ–网é،µو£€وµ‹IPن»£çگ†وک¯هگ¦هڈ¯ç”¨ه‘½ن»¤ï¼ڑ
cmd="curl -y 60 -Y 1 -m 300 -x $proxy -o $file_html$index $url_html"
$cmd
4م€پن؟هکIPن»£çگ†
و£€وµ‹ن¸€ن¸ھن»£çگ†IPوک¯هگ¦هڈ¯ç”¨ï¼Œه¦‚وœهڈ¯ç”¨ï¼Œهˆ™ن؟هکن¸‹و¥م€‚
هˆ¤و–ن¸€ن¸ھن»£çگ†IPوک¯هگ¦هڈ¯ç”¨çڑ„و ‡ه‡†ï¼Œوک¯é€ڑè؟‡هˆ¤و–و¥éھ¤3ن¸ن¸‹è½½çڑ„网é،µï¼ˆ$file_html$index)وک¯هگ¦وœ‰ه†…ه®¹ï¼Œه…·ن½“ه‘½ن»¤ه¦‚ن¸‹ï¼ڑ
if [ -e ./$file_html$index ]; then
echo $proxy >> $2
break;
fi
5م€پIPن»£çگ†وٹ“هڈ–网é،µ
هˆ©ç”¨و¥éھ¤4ن؟هکçڑ„ن»£çگ†IPوٹ“هڈ–网é،µï¼Œé€ڑè؟‡ن»£çگ†IPوٹ“هڈ–12ه›½وژ’هگچ网é،µه’Œو¸¸وˆڈ网é،µï¼Œه…·ن½“ه‘½ن»¤ه¦‚ن¸‹ï¼ڑ
proxy_cmd="curl -y 60 -Y 1 -m 300 -x $proxy -o $proxy_html $proxy_http"
$proxy_cmd
6م€پIPن»£çگ†و•…éڑœ
IPن»£çگ†و•…éڑœوœ‰ه¤ڑç§چوƒ…ه†µï¼Œهœ¨ن¸ٹé¢çڑ„é—®é¢کهˆ†وگن¸ه·²ç»ڈهˆ—ه‡؛ن؛†ه‡ و،,ن¸‹é¢ه°†è¯¦ç»†هˆ†وگه¦‚ن¸‹ï¼ڑ
aم€پن»£çگ†IPهœ¨وٹ“هڈ–çڑ„网é،µè؟‡ç¨‹ن¸ï¼Œçھپ然ه¤±و•ˆï¼Œو— و³•ç»§ç»ه®Œوˆگ网é،µوٹ“هڈ–
bم€پن»£çگ†IPو²،وœ‰ه¤±و•ˆï¼Œن½†وک¯وٹ“هڈ–网é،µه¾ˆو…¢ï¼Œو— و³•هœ¨ن¸€ه¤©24ه°ڈو—¶ه†…ه®Œوˆگ网é،µوٹ“هڈ–,ه¯¼è‡´و— و³•ç”ںوˆگو¸¸وˆڈوژ’هگچو¯ڈو—¥وٹ¥è،¨
cم€پن»£çگ†IPه…¨éƒ¨ه¤±و•ˆï¼Œو— è®؛وک¯è½®è¯¢و£€وµ‹ن¸€éپچوˆ–ه¤ڑéپچهگژ,都و— و³•ه®Œوˆگه½“ه¤©çڑ„网é،µوٹ“هڈ–ن»»هٹ،
dم€پç”±ن؛ژو•´ن¸ھ网络路由و‹¥ه،,ه¯¼è‡´ن»£çگ†IPوٹ“هڈ–网é،µه¾ˆو…¢وˆ–و— و³•وٹ“هڈ–,误هˆ¤ن¸؛ن»£çگ†IPه…¨éƒ¨ه¤±و•ˆï¼Œه¦‚ن½•وپ¢ه¤چه’Œç؛ و£
7م€پé‡چو–°و£€وµ‹IPن»£çگ†
هœ¨ç½‘é،µوٹ“هڈ–è؟‡ç¨‹ن¸ï¼Œé¢ه¯¹و¥éھ¤6çڑ„IPن»£çگ†و•…éڑœï¼Œè®¾è®،ن¸€ه¥—هگˆçگ†م€پé«کو•ˆçڑ„ن»£çگ†IPوٹ“هڈ–وپ¢ه¤چوœ؛هˆ¶ï¼Œوک¯و•´ن¸ھIPن»£çگ†ç›é€‰ç³»ç»ںçڑ„و ¸ه؟ƒه’Œه…³é”®
ه…¶و•…éڑœوپ¢ه¤چçڑ„轮询ç›é€‰وµپ程ه¦‚ن¸‹ï¼ڑ

ن¸ٹه›¾وµپ程ن¸ï¼Œéœ€è¦پو³¨و„ڈه‡ 点ï¼ڑ
aم€پ首ه…ˆو£€وµ‹ن¸ٹو¬،IPن»£çگ†ï¼Œè؟™وک¯ه› ن¸؛ن¸ٹو¬،(وک¨ه¤©ï¼‰çڑ„IPن»£çگ†ه®Œوˆگن؛†و‰€وœ‰ç½‘é،µوٹ“هڈ–ن»»هٹ،,ه…¶هڈ¯ç”¨و¦‚çژ‡ç›¸ه¯¹و¯”较é«ک,و‰€ن»¥ن¼که…ˆè€ƒè™‘ه…¶ن»ٹه¤©وک¯هگ¦ن¹ںهڈ¯ç”¨م€‚ه¦‚وœن¸چهڈ¯ç”¨ï¼Œهˆ™هڈ¦é€‰ه…¶ه®ƒ
bم€په¦‚وœن¸ٹو¬،ن»£çگ†IPن»ٹه¤©ن¸چهڈ¯ç”¨ï¼Œهˆ™é‡چو–°éپچهژ†و£€وµ‹ن»£çگ†IPو؛گ,ن¸€و—¦و£€وµ‹هˆ°وœ‰هڈ¯ç”¨ï¼Œهˆ™ن¸چه†چه¾ھçژ¯ن¸‹هژ»ï¼Œو›´و–°هڈ¯ç”¨IPن»£çگ†ه¹¶ن؟هکه…¶هœ¨IPو؛گçڑ„ن½چ置,و–¹ن¾؟ن¸‹و¬،ن»ژو¤ه¤„ه¼€ه§‹éپچهژ†
cم€په¦‚وœوµپ程bو–°é€‰çڑ„ن»£çگ†IPçھپ然ه¤±و•ˆوˆ–网é€ںè؟‡و…¢ï¼Œهˆ™هœ¨bè®°ه½•çڑ„IPو؛گن½چ置继ç»ç›é€‰هگژé¢çڑ„ن»£çگ†IPوک¯هگ¦هڈ¯ç”¨م€‚ه¦‚هڈ¯ç”¨ï¼Œهˆ™ç»§ç»وٹ“هڈ–网é،µï¼›ه¦‚ن¸چهڈ¯ç”¨ï¼Œهˆ™ه†چو¬،éپچهژ†و•´ن¸ھIPو؛گ
dم€په¦‚وœه†چو¬،éپچهژ†ن؛†و•´ن¸ھن»£çگ†IPو؛گ,ن»چ然و²،وœ‰ن»£çگ†IPهڈ¯ç”¨ï¼Œهˆ™هڈچه¤چ轮询éپچهژ†و•´ن¸ھن»£çگ†IPو؛گ,直هˆ°وœ‰ن»£çگ†IPهڈ¯ç”¨وˆ–ن»ٹه¤©24و—¶è؟‡هژ»ï¼ˆهچ³ن»ٹو—¥و•´ه¤©éƒ½و‰¾ن¸چهˆ°هڈ¯ç”¨ن»£çگ†IP)
eم€په¯¹وµپ程dن¸ه…¨éƒ¨ن»£çگ†IPه¤±و•ˆن¸”و•´و—¥و‰¾ن¸چهˆ°هڈ¯ç”¨ن»£çگ†IP,و— و³•ه®Œوˆگه½“و—¥ç½‘é،µوٹ“هڈ–è؟™ن¸€ç‰¹و®ٹوƒ…ه†µï¼Œهœ¨و¬،و—¥ه‡Œو™¨é‡چو–°هگ¯هٹ¨ç½‘é،µوٹ“هڈ–و€»وژ§è„ڑوœ¬ه‰چ,需è¦په…ˆو€و»وµپ程dهœ¨هگژهڈ°çڑ„ه¾ھçژ¯è؟›ç¨‹ï¼Œéک²و¢ن»ٹو—¥ه’Œو¬،و—¥çڑ„ن¸¤ن¸ھهگژهڈ°ç½‘é،µوٹ“هڈ–程ه؛ڈهگŒو—¶è؟گè،Œï¼ˆç›¸ه½“ن؛ژن¸¤ن¸ھه¼‚و¥çڑ„هگژهڈ°وٹ“هڈ–è؟›ç¨‹ï¼‰ï¼Œé€ وˆگوٹ“هڈ–网é،µوژ’هگچو•°وچ®é™ˆو—§وˆ–错误م€پهچ 用网é€ںه¸¦ه®½ç‰م€‚ه…¶ه®çژ°و€و»ه½“و—¥هƒµو»çڑ„هگژهڈ°وٹ“هڈ–è؟›ç¨‹ï¼Œè¯·è§پن¸ٹن¸€ç¯‡هچڑه®¢Linux وٹ“هڈ–网é،µه®ن¾‹ ——م€‹è‡ھهٹ¨هŒ–و€»وژ§è„ڑوœ¬ ——م€‹kill_curl.shè„ڑوœ¬ï¼Œه…¶هژںçگ†وک¯kill -9 è؟›ç¨‹هڈ·ï¼Œه…³é”®è„ڑوœ¬ن»£ç په¦‚ن¸‹ï¼ڑ
while [ ! -z $(ps -ef | grep curl | grep -v grep | cut -c 9-15) ]
do
ps -ef | grep curl | grep -v grep | cut -c 15-20 | xargs kill -9
ps -ef | grep curl | grep -v grep | cut -c 9-15 | xargs kill -9
done
8م€په®Œوˆگ网é،µوٹ“هڈ–
é€ڑè؟‡ن¸ٹè؟°çڑ„IPن»£çگ†ç›é€‰ç³»ç»ں,ç›é€‰ه‡؛12ه›½هڈ¯ç”¨çڑ„ه…چè´¹ن»£çگ†IP,ه®Œوˆگو¯ڈو—¥12ه›½ç½‘é،µوژ’هگچه’Œو¸¸وˆڈ网é،µçڑ„وٹ“هڈ–ن»»هٹ،
ن¹‹هگژ,ه°±وک¯ه¯¹ç½‘é،µن¸و¸¸وˆڈه±و€§ن؟،وپ¯çڑ„è؟›è،Œوڈگهڈ–م€په¤„çگ†ï¼Œç”ںوˆگو¯ڈو—¥وٹ¥è،¨م€پé‚®ن»¶ه®ڑو—¶هڈ‘é€په’Œè¶‹هٹ؟ه›¾وں¥è¯¢ç‰ï¼Œè¯¦è§پوˆ‘çڑ„ن¸ٹن¸€ç¯‡هچڑه®¢ï¼ڑLinux وٹ“هڈ–网é،µه®ن¾‹
è„ڑوœ¬هٹں能ه®çژ°
IPن»£çگ†ç›é€‰çڑ„هں؛وœ¬è؟‡ç¨‹و¯”较简هچ•ï¼Œه…¶و•°وچ®و ¼ه¼ڈه’Œه®çژ°و¥éھ¤ه¦‚ن¸‹ï¼ڑ
首ه…ˆï¼Œهˆ°freeproxylists.net 网站,و”¶é›†هڈ¯ç”¨çڑ„ن»£çگ†IPو؛گ(ن»¥ç¾ژه›½ن¸؛ن¾‹ï¼‰ï¼Œه…¶و ¼ه¼ڈه¦‚ن¸‹ï¼ڑ

وژ¥ç€ï¼Œو¸…除ن¸ٹه›¾ن¸çڑ„ç©؛و ¼ï¼Œه…·ن½“ه®çژ°ه‘½ن»¤è¯·è§پن¸ٹé¢م€گو–¹و،ˆè®¾è®،م€‘——م€‹م€گ2م€پو–‡وœ¬é¢„ه¤„çگ†م€‘,و–‡وœ¬é¢„ه¤„çگ†هگژçڑ„و ¼ه¼ڈه¦‚ن¸‹ï¼ڑ

然هگژ,وµ‹è¯•ن¸ٹه›¾و–‡وœ¬é¢„ه¤„çگ†هگژçڑ„ن»£çگ†IPوک¯هگ¦هڈ¯ç”¨ه…·ن½“ه‘½ن»¤è¯·è§پن¸ٹé¢م€گو–¹و،ˆè®¾è®،م€‘——م€‹م€گ3م€پو£€وµ‹IPن»£çگ†م€‘,و£€وµ‹ن»£çگ†IPهگژçڑ„و ¼ه¼ڈه¦‚ن¸‹ï¼ڑ

ن¸‹é¢ن»‹ç»چshellè„ڑوœ¬ه®çژ°و–‡وœ¬é¢„ه¤„çگ†ه’Œç½‘é،µç›é€‰çڑ„详细و¥éھ¤
1م€پو–‡وœ¬é¢„ه¤„çگ†
# file process
log='Top800proxy.log'
dtime=$(date +%Y-%m-%d__%H:%M:%S)
function select_proxy(){
if [ ! -d $dir_split ]; then
mkdir $dir_split
fi
if [ ! -d $dir_output ]; then
mkdir $dir_output
fi
if [ ! -e $log ]; then
touch $log
fi
echo "================== Top800proxy $dtime ==================" >> $log
for file in `ls $dir_input`; do
echo $file >> $log
file_input=$dir_input$file
echo $file_input >> $log
file_split=$dir_split$file"_split"
echo $file_split >> $log
rm -rf $file_split
touch $file_split
sed -e "s/\s\{2,\}/:/g" $file_input > $file_split
sed -i "s/ /:/g" $file_split
file_output=$dir_output$file"_out"
echo $file_output >> $log
proxy_output "$file_split" "$file_output"
echo '' >> $log
done
echo '' >> $log
}
è„ڑوœ¬هٹں能说وکژï¼ڑ
ifè¯هڈ¥ï¼Œهˆ¤و–ه¹¶هˆ›ه»؛用ن؛ژن؟هکه¤„çگ†IPو؛گن¸é—´ç»“وœçڑ„و–‡ن»¶ه¤¹$dir_split ه’Œ$dir_output ,ه‰چ者ن؟هکم€گè„ڑوœ¬هٹں能ه®çژ°م€‘ن¸و–‡وœ¬é¢„ه¤„çگ†هگژçڑ„و–‡وœ¬و ¼ه¼ڈ,هگژ者ن؟هکو£€وµ‹هگژهڈ¯ç”¨çڑ„ن»£çگ†IP
sed -eè¯هڈ¥ï¼Œوٹٹ输ه…¥و–‡وœ¬ï¼ˆè„ڑوœ¬هٹں能ه®çژ°çڑ„ه›¾1)ن¸çڑ„ه¤ڑن¸ھç©؛و ¼ï¼Œن؟®و”¹ن¸؛ن¸€ن¸ھه—符“:â€
sed -iè¯هڈ¥ï¼Œè؟›ن¸€و¥وٹٹو–‡وœ¬ن¸çڑ„ه¤ڑن½™ç©؛و ¼ï¼Œè½¬وچ¢ن¸؛ن¸€ن¸ھه—符":"
转وچ¢çڑ„ن¸é—´ç»“وœï¼Œéƒ½ن؟هکهˆ°و–‡ن»¶ه¤¹$dir_split
هگژé¢çڑ„file_outputن¸‰è،Œï¼Œن»¥و–‡ن»¶هڈ‚و•°çڑ„ه½¢ه¼ڈ"$file_split",ن¼ ç»™ن»£çگ†IPو£€وµ‹ه‡½و•°ï¼ˆproxy_output),ç›é€‰ه‡؛هڈ¯ç”¨çڑ„ن»£çگ†IP
2م€پن»£çگ†IPç›é€‰
index=1
file_html=$dir_output"html_"
cmd=''
function proxy_output(){
rm -rf $2
touch $2
rm -rf $file_html*
index=1
while read line
do
proxy_ip=$(echo $line | cut -f 1 -d ":")
proxy_port=$(echo $line | cut -f 2 -d ":")
proxy=$proxy_ip":"$proxy_port
echo $proxy >> $log
cmd="curl -y 60 -Y 1 -m 300 -x $proxy -o $file_html$index $url_html"
echo $cmd >> $log
$cmd
if [ -e ./$file_html$index ]; then
echo $proxy >> $2
break;
fi
index=`expr $index + 1`
done < $1
rm -rf $file_html*
}
è„ڑوœ¬هٹں能说وکژï¼ڑ
ن»£çگ†IPç›é€‰ه‡½و•°proxy_outputه¤´ن¸‰è،Œï¼Œو¸…除ه…ˆه‰چç›é€‰çڑ„结وœï¼Œن½œç”¨وک¯هˆه§‹هŒ–
whileه¾ھçژ¯ï¼Œن¸»è¦پوک¯éپچهژ†ن»¥هڈ‚و•°ه½¢ه¼ڈن¼ ه…¥çڑ„و–‡وœ¬é¢„ه¤„çگ†هگژçڑ„"$file_split",و£€وµ‹ن»£çگ†IPوک¯هگ¦هڈ¯ç”¨ï¼Œه…¶و¥éھ¤ه¦‚ن¸‹ï¼ڑ
aم€پ首ه…ˆو‹¼وژ¥ه‡؛ن»£çگ†IPçڑ„(ip:port)و ¼ه¼ڈ,ه…¶ه®çژ°وک¯é€ڑè؟‡cutهˆ†ه‰²و–‡وœ¬è،Œï¼Œç„¶هگژوڈگهڈ–ه‡؛第ن¸€ن¸ھه—و®µï¼ˆip)ه’Œç¬¬ن؛Œن¸ھه—و®µï¼ˆport),و‹¼وژ¥وˆگ(ip:port)
bم€پé€ڑè؟‡curlو„é€ ه‡؛وٹ“هڈ–网é،µçڑ„ه‘½ن»¤cmd,و‰§è،Œç½‘é،µن¸‹è½½ه‘½ن»¤$cmd
cم€پé€ڑè؟‡و£€وµ‹ç½‘é،µن¸‹è½½ه‘½ن»¤و‰§è،Œهگژ,وک¯هگ¦ç”ںوˆگن؛†ç½‘é،µن¸‹è½½و–‡ن»¶ï¼Œو¥هˆ¤و–و‹¼وژ¥ه‡؛çڑ„ن»£çگ†IP($proxy)وک¯هگ¦وœ‰و•ˆم€‚è‹¥وœ‰و•ˆï¼Œهˆ™ن؟هکو¤ن»£çگ†IPهˆ°"$file_output"ن¸ه¹¶é€€ه‡؛éپچهژ†(break)
dم€په¦‚وœه½“ه‰چن»£çگ†IPو— و•ˆï¼Œهˆ™è¯»هڈ–ن¸‹ن¸€è،Œن»£çگ†IP,继ç»و£€وµ‹
ن»£çگ†IPوٹ“هڈ–网é،µه®ن¾‹ï¼ڑ
هˆ©ç”¨ن¸ٹé¢çڑ„ن»£çگ†IPç³»ç»ں,ç›é€‰ه‡؛و¥ه…چè´¹ن»£çگ†IP,وٹ“هڈ–و¸¸وˆڈوژ’هگچ网é،µçڑ„ه®ن¾‹ه¦‚ن¸‹ï¼ˆè„ڑوœ¬ç‰‡و®µï¼‰ï¼ڑ
index=0
while [ $index -le $TOP_NUM ]
do
url=$url_start$index$url_end
url_cmd='curl -y 60 -Y 1 -m 300 -x '$proxy' -o '$url_output$index' '$url
echo $url_cmd
date=$(date "+%Y-%m-%d___%H-%M-%S")
echo $index >> $log
echo $url"___________________$date" >> $log
$url_cmd
# done timeout file
seconds=0
while [ ! -f $url_output$index ]
do
sleep 1
echo $url_output$index"________________no exist" >> $log
$url_cmd
seconds=`expr $seconds + 1`
echo "seconds____________"$seconds >> $log
if [ $seconds -ge 5 ]; then
select_proxy
url_cmd='curl -y 60 -Y 1 -m 300 -x '$proxy' -o '$url_output$index' '$url
seconds=0
fi
done
index=`expr $index + 24`
done
è„ڑوœ¬هٹں能说وکژï¼ڑ
ن¸ٹé¢shellè„ڑوœ¬ن»£ç پ片و®µï¼Œوک¯ç”¨و¥وٹ“هڈ–网é،µçڑ„,ه…¶ن¸وœ€و ¸ه؟ƒçڑ„ن¸€è،Œوک¯select_proxy
ه…¶ن½œç”¨وک¯ن¸ٹè؟°ن»‹ç»چè؟‡çڑ„,ه½“ن»£çگ†IPçھپ然ه¤±و•ˆم€پوٹ“هڈ–网é،µè؟‡و…¢م€په…¨éƒ¨ن»£çگ†IP都و— و•ˆم€پوˆ–و— و³•ه®Œوˆگه½“ه¤©çڑ„网é،µوٹ“هڈ–ه·¥ن½œï¼Œç”¨و¥é‡چو–°ç›é€‰ن»£çگ†IP,وپ¢ه¤چ网é،µوٹ“هڈ–çڑ„ن¸€و®µو ¸ه؟ƒن»£ç پ
ه…¶è®¾è®،ه®çژ°وµپ程,ه¦‚ن¸ٹè؟°çڑ„م€گو–¹و،ˆè®¾è®،م€‘——م€‹م€گ7م€پé‡چو–°و£€وµ‹IPن»£çگ†م€‘,ه…¶ه®çژ°هژںçگ†هڈ¯هڈ‚ç…§ن¸ٹè؟°çڑ„م€گن»£çگ†IPç›é€‰م€‘çڑ„è„ڑوœ¬ï¼Œهœ¨و¤ن¸چه†چè´´ه‡؛ه…¶و؛گè„ڑوœ¬ن»£ç پ
هˆ†ن؛«هˆ°ï¼ڑ




相ه…³وژ¨èچگ
هں؛ن؛ژlinux+lnmp+apache+proxy+PHPه¤ڑ版وœ¬çڑ„webه¼€هڈ‘çژ¯ه¢ƒوگه»؛ï¼پ
Paros+proxyï¼ڑ网é،µç¨‹ه؛ڈو¼ڈو´è¯„ن¼°ن»£çگ†
Zabbix-5.0部署+proxy(ن»£çگ†).docx
LAMP+Proxy+读ه†™هˆ†ç¦» هں؛ن؛ژن¼پن¸ڑه®وˆک هŒ…و‹¬ه®‰è£… é…چç½® ن¼کهŒ– vipن¸“ن؛«
mysql +mmm + proxyه®çژ°è¯»ه†™هˆ†ç¦» ,و•°وچ®ه؛“ه®çژ°è¯»ه†™هˆ†ç¦»
proxyو؛گن»£ç پ,linuxن¸‹çڑ„ftp ن»£çگ†çڑ„و؛گن»£ç پ,ه¤§ه®¶ه¤ڑه¤ڑو”¯وŒپه•ٹ
ه…¬هڈ¸è؟گç»´و‰‹ه†Œï¼Œه®‰è£…LAP+mysqlن¸»ن»ژه؛“ apache+mysql+proxyن¸»ن»ژ+PHP+discuzè®؛ه›ï¼Œه؛ںè¯ن¸چه¤ڑ说,ن¸ٹه¹²è´§ï¼پ
ن¸چçں¥éپ“ه®کو–¹ن½œè€…ن¸؛ن»€ن¹ˆن¸چهٹ ن¸ٹن»£çگ†هٹں能,و¤ç‰ˆوœ¬و£ه¥½هٹ ن¸ٹن؛†ن»£çگ†IPهٹں能ن½؟用و–¹و³•ه¦‚:Jsoup.connect(urls).proxy(Proxy.Type.HTTP, "ipهœ°ه€", 8080)
ه†…网ç©؟é€ڈ,c++ه®çژ°ï¼Œو— 需ه…¬ç½‘IP,ه°ڈه·§ï¼Œوک“用,ه؟«é€ں,ه®‰ه…¨ï¼Œوœ€ه¥½çڑ„ه¤ڑ链路èپڑهگˆï¼ˆp2p+proxy)و¨،ه¼ڈ,è؟™و‰چوک¯ن½ çœںو£وƒ³è¦پçڑ„ه†…网ç©؟é€ڈه·¥ه…·ï¼پ.zip
Java ه®çژ°ه…چè´¹ن»£çگ†IPçڑ„èژ·هڈ–و–¹ه¼ڈ ه¹¶هٹ¨و€په®و—¶و ،éھŒوک¯هگ¦وœ‰و•ˆï¼Œjavaو–‡ن»¶é،¹ç›®ه†…هگ«وœ‰Jsoup...ه…¶ن؛Œï¼ڑه¯¹ه·²ن¸‹è½½هˆ°وœ¬هœ°çڑ„ن»£çگ†IPè؟›è،Œه†چç›é€‰ï¼Œه¯¹ه¤±و•ˆçڑ„ن»£çگ†IPè؟›è،Œه¤„çگ†ï¼Œه¯¹ن»»ç„¶وœ‰و•ˆçڑ„ipè؟›è،Œن؟هک 结è¯ï¼ڑه¦‚وœه¯¹ن½ وœ‰ه¸®هٹ©ï¼Œè¯·ن¸؛وˆ‘评è®؛点èµ
spider hash è®،ç®—ه™¨ è؟کوœ‰ن¸€ن¸ھهڈ¯ن»¥وµ‹è¯•ه¸¸è§پçڑ„Webه؛”用程ه؛ڈو”»ه‡» ه¦‚SQLو³¨ه…¥ه¼ڈو”»ه‡»ه’Œè·¨ç«™è„ڑوœ¬و”»ه‡» çڑ„و‰«وڈڈه™¨ ">ه®‰ه…¨وµ‹è¯•ه·¥ه…· ن¸€ن¸ھه¯¹Webه؛”用程ه؛ڈçڑ„و¼ڈو´è؟›è،Œè¯„ن¼°çڑ„ن»£çگ†ç¨‹ه؛ڈ هچ³ن¸€ن¸ھهں؛ن؛ژJavaçڑ„webن»£çگ†ç¨‹ه؛ڈ هڈ¯ن»¥è¯„ن¼°Webه؛”用程ه؛ڈ...
ن¸€و¬¾ه¾ˆه¥½ç”¨çڑ„ن»£çگ†è½¯ن»¶م€‚ وڈگن¾›ه¸¸ç”¨ه¸¸è§پ软ن»¶ن¸‹è½½ï¼Œه°ڈه·§ه®ç”¨çڑ„ه°ڈ软ن»¶م€په°ڈه·¥ه…·ï¼Œ çƒé—¨ه؟…ه¤‡ç²¾ه“پ软ن»¶ç‰ï¼Œن¸؛ه°½هڈ¯èƒ½çڑ„و–¹ن¾؟用وˆ·ن½؟用,软 ن»¶ه¤ڑن¸؛ه…چ费软ن»¶وˆ–ç»؟色版,ه¹¶é™„ن¸ٹهژںهˆ›çڑ„软ن»¶ن½“éھŒه؟ƒ ه¾—هڈٹن»‹ç»چم€‚
该软ن»¶هŒ…وک¯apacheçڑ„httpdن¸mod_proxy.soم€پmod_proxy_http.soن»£çگ†و¨،ه—,هˆ†هˆ«ه¯¹ه؛”هŒ…هگ«linuxم€پwindowsçڑ„版وœ¬م€‚
3. ه®ڑو—¶وµ‹è¯•ه’Œç›é€‰ï¼Œه‰”除ن¸چهڈ¯ç”¨ن»£çگ†ï¼Œç•™ن¸‹هڈ¯ç”¨ن»£çگ† 4. وڈگن¾›ن»£çگ† API,éڑڈوœ؛هڈ–用وµ‹è¯•é€ڑè؟‡çڑ„هڈ¯ç”¨ن»£çگ† è؟گè،Œو–¹ه¼ڈï¼ڑ 1. Docker 2. Python+Redis Github 链وژ¥ï¼ڑhttps://github.com/Python3WebSpider/ProxyPool 详وƒ…éک…读ï¼ڑ...
ن½؟用mysql5.7+sharding-proxyه®çژ°هˆ†è،¨ï¼Œç–ç•¥ن¸؛و¯ڈهچٹه¹´و—¶é—´هˆ†ن¸€و¬،è،¨
èژ·هڈ–网络资و؛گ,ن½؟用هٹ¨و€پن»£çگ†ip解ه†³هچ•ن¸ھipè®؟é—®و¬،و•°é™گهˆ¶é—®é¢ک
2019.03-Proxy_Poolè‡ھهٹ¨هŒ–ن»£çگ†وگœé›†+评ن¼°+هکه‚¨+ه±•ç¤؛ه·¥ه…·1
ه…چè´¹IPن»£çگ†ه·¥ه…·ه…چ费版هڈ¯ن»¥ن¸€é”®èژ·هڈ–ن»£çگ†ç»ه¯¹ه…چè´¹
dbgpProxy linux版 php dbgp proxy
Linuxçڑ„ه®‰è£…ه’Œهگ¯هٹ¨ï¼Œç”¨وˆ·ç®،çگ†ï¼ŒShell编程وٹ€وœ¯ï¼Œè؟›ç¨‹ç®،çگ†ï¼ŒC编译ه™¨ï¼Œç³»ç»ںو‰©ه……,维وٹ¤ن¸ژ监视,Linuxçڑ„ه›¾ه½¢ç•Œé¢ï¼Œç½‘络çڑ„هں؛وœ¬و¦‚ه؟µن¸ژ设置,Linuxهœ¨ç½‘络资و؛گه…±ن؛«ه’Œç”µهگé‚®ن»¶و–¹é¢çڑ„ه؛”用,ن»¥هڈٹDNSم€پFTPم€پWebه’ŒProxyوœچهٹ،ه™¨ç‰...