жңҖиҝ‘е·ҘдҪңйңҖиҰҒејҖе§Ӣз ”з©¶mongoDBпјҢжҲ‘еҮҶеӨҮд»Һе…¶жәҗд»Јз Ғи§’еәҰпјҢеҜ№дәҺmongodе’ҢmongosжңҚеҠЎзҡ„жһ¶жһ„гҖҒshardingзӯ–з•ҘгҖҒreplicasetзӯ–з•ҘгҖҒж•°жҚ®еҗҢжӯҘе®№зҒҫгҖҒзҙўеј•зӯүжңәеҲ¶еҒҡдёҖдёӘжң¬иҙЁжҖ§зҡ„дәҶи§ЈгҖӮе…¶д»Јз ҒзәҰ20дёҮиЎҢпјҲжҲ‘з ”з©¶зҡ„жҳҜ2.0.6зүҲжң¬жәҗз ҒпјүпјҢжң¬зҜҮе…Ҳд»Һmongodзҡ„еҗҜеҠЁжөҒзЁӢиҜҙиө·пјҢе®ғжң¬жҳҜдёҖдёӘеӨҡзәҝзЁӢзЁӢеәҸпјҢжүҖд»Ҙжң¬ж–ҮеңЁдәҺиҜҙжҳҺmongodжңүеӨҡе°‘дёӘзәҝзЁӢпјҢжҜҸдёӘзәҝзЁӢзҡ„ж„Ҹд№үжүҖеңЁгҖӮеёҢжңӣеӨ§е®¶йҳ…иҜ»жң¬ж–Үж—¶е…іжіЁеңЁmongodзҡ„еӨ–еӣҙжЎҶжһ¶пјҢжҡӮдёҚж¶үеҸҠж•°жҚ®ж–Ү件зҡ„з»„з»ҮгҖҒзҙўеј•Bж ‘зҡ„з»„з»ҮзӯүпјҢд»…focus inеңЁзҪ‘з»ңжЎҶжһ¶гҖҒзәҝзЁӢжЁЎеһӢдёҠгҖӮ
еј„жё…жҘҡиҝҷзӮ№зҡ„еҘҪеӨ„еҫҲжҳҺжҳҫпјҡд№ӢеҗҺе°ұеҸҜд»Ҙжңүзҡ„ж”ҫзҹўзҡ„з ”з©¶mongodжҹҗдёӘжЁЎеқ—究з«ҹжҳҜеҰӮдҪ•е®һзҺ°зҡ„пјҢеҸҜд»Ҙеҝ«йҖҹзҡ„и·іеҲ°зӣёеә”зҡ„зұ»дёӯйҳ…иҜ»жәҗз ҒпјҢи§ЈеҶіжҲ‘们еңЁдә§е“Ғдёӯзҡ„е®һйҷ…й—®йўҳгҖӮжҲ‘и®ӨдёәиҝҷжҳҜз ”з©¶е…¶еәһеӨ§жәҗз ҒдёҖдёӘеҘҪзҡ„ејҖе§ӢгҖӮ
еңЁиҜҙжҳҺmongodеүҚпјҢйЎ»дәҶи§ЈmongoDBеӨ§йҮҸд»Јз ҒжҳҜеҹәдәҺboostеә“жһ„е»әзҡ„пјҢеӣ жӯӨиҝҷйҮҢе…ҲиЎҢеҜ№boostеә“е»әз«ӢзәҝзЁӢеҒҡдёӘз®ҖеҚ•зҡ„дәҶи§ЈгҖӮ
1гҖҒboostеә“еҰӮдҪ•е»әз«ӢзәҝзЁӢ
boost::threadжҳҜboostдёӯи·Ёе№іеҸ°зҡ„еӨҡзәҝзЁӢеә“пјҢmongoDBеҲӣе»әзәҝзЁӢж—¶еӨ§еӨҡж•°жғ…еҶөдёӢжҳҜдҪҝз”Ёthreadеә“зҡ„пјҲе°‘йҮҸжғ…еҶөзӣҙжҺҘи°ғз”Ёpthread_createж–№жі•пјүпјҢдё»иҰҒдҪҝз”ЁдәҶд»ҘдёӢдёӨз§Қж–№ејҸпјҡ
пјҲ1пјүзӣҙжҺҘиҝҗиЎҢи®©зәҝзЁӢиҝҗиЎҢfunc
дҫӢеҰӮdurThreadзәҝзЁӢпјҡ
void durThread() {
while( !inShutdown() ) { ... }
}
boost::thread t(durThread);
пјҲ2пјүеңЁзұ»дёӯе®ҡд№үйқҷжҖҒзҡ„runж–№жі•пјҢи°ғз”ЁthreadеҲӣе»әзәҝзЁӢ
class FileAllocator : boost::noncopyable {
static void run( FileAllocator * fa );
void FileAllocator::start() {
boost::thread t( boost::bind( &FileAllocator::run , this ) );
}
};
2гҖҒmongodзҡ„е…ҘеҸЈ
mongodзҡ„е…ҘеҸЈmainеҮҪж•°еңЁsrc/mongo/db/db.cppж–Ү件дёӯпјҢжҲ‘з”»дәҶдёӘз®ҖеҚ•зҡ„жҙ»еҠЁеӣҫз®ҖиҰҒд»Ӣз»Қе…¶еҗҜеҠЁжөҒзЁӢпјҡ
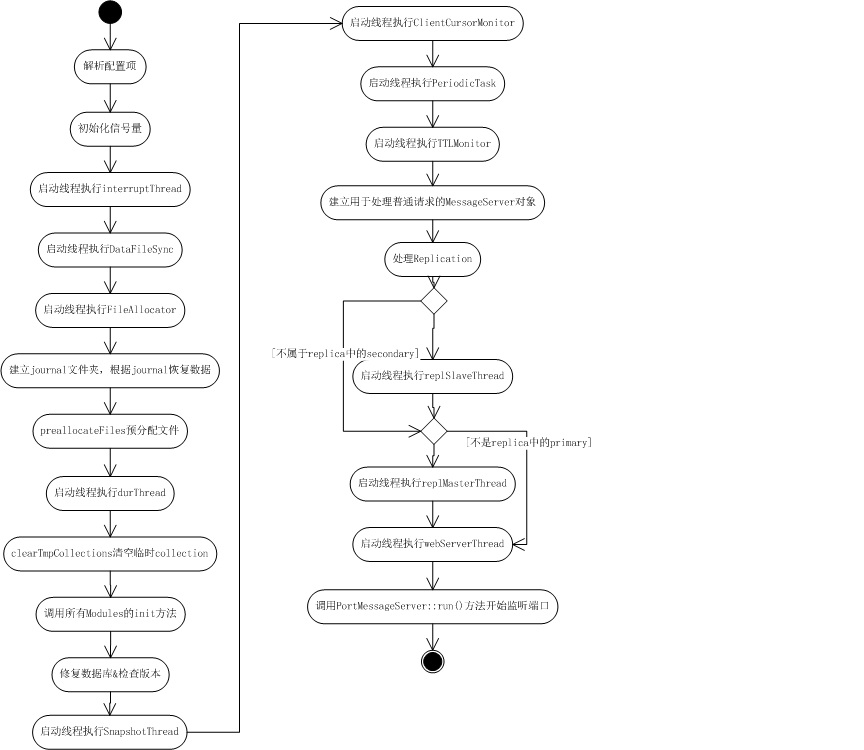
еҰӮдёҠеӣҫжүҖзӨәпјҢиҝҷйҮҢеҮәзҺ°дәҶ12дёӘеӣәе®ҡзәҝзЁӢпјҢиҝҳжІЎжңүеҢ…жӢ¬mongodиҝҗиЎҢд»ҘеҗҺеӨ„зҗҶиҜ·жұӮж—¶жҙҫз”ҹеҮәжқҘзҡ„зәҝзЁӢпјҢеҰӮдёӢжүҖзӨәпјҡ
вҖ“ interruptThread
вҖ“ DataFileSync::run
вҖ“ FileAllocator::run
вҖ“ durThread
вҖ“ SnapshotThread::run
вҖ“ ClientCursorMonitor::run
вҖ“ PeriodicTask::Runner::run
вҖ“ TTLMonitor::run
вҖ“ replSlaveThread
вҖ“ replMasterThread
вҖ“ webServerThread
вҖ“ еӨ„зҗҶж•°жҚ®еә“иҜ·жұӮзҡ„дё»зәҝзЁӢ
еҰӮжһңдёҚеұһдәҺд»»дҪ•replica setпјҢйӮЈд№ҲиҮіе°‘жңү10дёӘеӣәе®ҡзәҝзЁӢпјҲеҺ»йҷӨreplSlaveThreadе’ҢreplMasterThreadпјүгҖӮ
дёӢйқўжҲ‘们е…Ҳи®Ёи®әиҝҷ10дёӘеӣәе®ҡзҡ„зәҝзЁӢпјҢеҶҚи®Ёи®әжҖ§иғҪйқһеёёејұзҡ„зӣ‘еҗ¬webдәӢ件зҡ„зәҝзЁӢжҳҜжҖҺж ·еӨ„зҗҶиҜ·жұӮзҡ„пјҢжңҖеҗҺи®Ёи®әжҖ§иғҪзЁҚеҘҪдёҖзӮ№зҡ„дё»жңҚеҠЎзәҝзЁӢжҳҜжҖҺж ·еӨ„зҗҶиҜ·жұӮзҡ„гҖӮ
3гҖҒ5дёӘеҹәдәҺBackgroundJobзұ»е®һзҺ°зҡ„е·ҘдҪңзәҝзЁӢ
иҝҷ5дёӘзәҝзЁӢеҲҶеҲ«жҳҜDataFileSync,SnapshotThread, ClientCursorMonitor, TTLMonitor, PeriodicTaskпјҢзұ»еӣҫеҰӮдёӢжүҖзӨәпјҡ
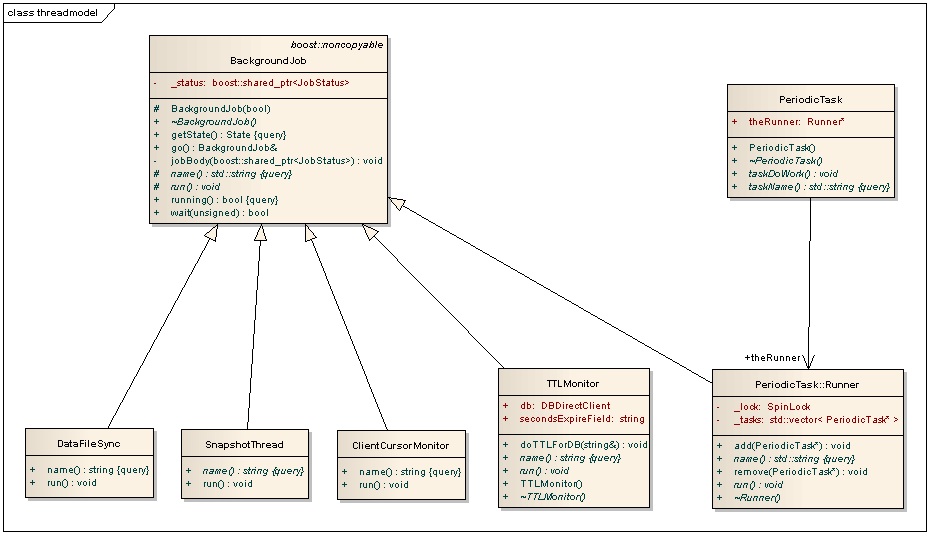
дёҠйқўиҝҷ5дёӘзұ»д№ҹжҳҜз”Ёboost::threadfunctionж–№жі•еҲӣе»әзәҝзЁӢиҝҗиЎҢзҡ„пјҢе®ғ们继жүҝдәҶBackgroundJobзұ»пјҢдҪҝз”Ёgoж–№жі•еҗҜеҠЁзәҝзЁӢжү§иЎҢjobBodyе°ұжҳҜеңЁеҗҜеҠЁзәҝзЁӢжү§иЎҢrunж–№жі•пјҢеҰӮдёӢжүҖзӨәпјҡ
BackgroundJob& BackgroundJob::go() {
boost::thread t( boost::bind( &BackgroundJob::jobBody , this, _status ) );
return *this;
}
void BackgroundJob::jobBody( boost::shared_ptr<JobStatus> status ) {
...
run();
...
}
иҝҷдәӣзәҝзЁӢзҡ„ж„Ҹд№үеҰӮдёӢпјҡ
DataFileSyncдё»иҰҒеңЁи°ғз”ЁMemoryMappedFile::flushж–№жі•е°ҶеҶ…еӯҳдёӯзҡ„ж•°жҚ®еҲ·еҲ°зЈҒзӣҳдёҠгҖӮ жҲ‘们зҹҘйҒ“пјҢmongodbжҳҜи°ғз”ЁmmapжҠҠзЈҒзӣҳдёӯзҡ„ж•°жҚ®жҳ е°„еҲ°еҶ…еӯҳдёӯзҡ„пјҢжүҖд»Ҙеҝ…йЎ»жңүдёҖдёӘжңәеҲ¶ж—¶еҲ»зҡ„еҲ·ж•°жҚ®еҲ°зЎ¬зӣҳжүҚиғҪдҝқиҜҒеҸҜйқ жҖ§пјҢеӨҡд№…еҲ·дёҖж¬ЎжҳҜдёҺsyncdelayеҸӮж•°зӣёе…ізҡ„гҖӮ
SnapshotThreadе°Ҷз”ҹжҲҗеҝ«з…§ж–Ү件帮еҠ©еҝ«йҖҹжҒўеӨҚгҖӮ
ClientCursorMonitorе°Ҷз®ЎзҗҶз”ЁжҲ·зҡ„жёёж ҮпјҢжҜҸ4з§’и°ғз”ЁдёҖж¬ЎidleTimeReport()ж–№жі•пјҢжҜҸдёҖеҲҶй’ҹи°ғз”ЁsayMemoryStatus()ж–№жі•гҖӮ
TTLMonitorз®ЎзҗҶTTLпјҢйҖҡиҝҮи°ғз”ЁdoTTLForDB()ж–№жі•жЈҖжҹҘжүҖжңүdbгҖӮ
PeriodicTaskе°Ҷд»ҺеҠЁжҖҒж•°з»„std::vector<PeriodicTask* > _tasksдёӯиҺ·еҸ–е‘ЁжңҹжҖ§д»»еҠЎжү§иЎҢгҖӮ
4гҖҒ5дёӘзӣҙжҺҘжҸҗдҫӣе…ЁеұҖж–№жі•жү§иЎҢзҡ„зәҝзЁӢ

FileAllocatorз”ЁдәҺеҲҶй…Қж–°ж–Ү件пјҢе®ғеҶіе®ҡеҲҶй…Қж–Ү件зҡ„еӨ§е°ҸпјҢдҫӢеҰӮз”Ёзҝ»еҖҚзҡ„ж–№ејҸгҖӮ
interruptThreadеҸӘеӨ„зҗҶдҝЎеҸ·йҮҸгҖӮ
durThreadеҒҡжү№йҮҸжҸҗдәӨе’Ңеӣһж»ҡе·ҘдҪңгҖӮ
replSlaveThreadжҳҜеҪ“еүҚз»“зӮ№дҪңдёәsecondaryж—¶зҡ„еҗҢжӯҘзәҝзЁӢгҖӮ
replMasterThreadжҳҜеҪ“еүҚз»“зӮ№дҪңдёәmasterж—¶зҡ„еҗҢжӯҘзәҝзЁӢгҖӮ
5гҖҒwebзӣ‘еҗ¬зәҝзЁӢ
mongodжҳҜеҰӮдҪ•еӨ„зҗҶwebиҜ·жұӮзҡ„е‘ўпјҹе®ғжҳҜйҖҡиҝҮзҪ‘з»ңжЎҶжһ¶дёӯзҡ„ж ёеҝғзұ»Listernerе®һзҺ°зҡ„пјҢзұ»еӣҫеҰӮдёӢжүҖзӨәпјҡ
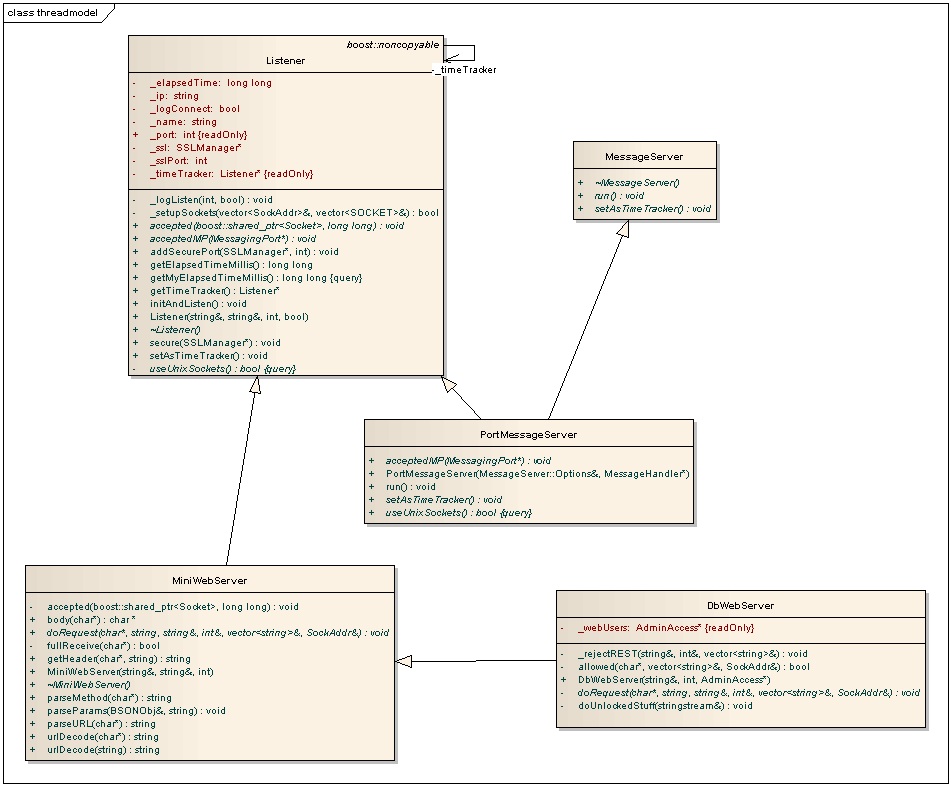
жҖҺд№ҲзҗҶи§Јиҝҷе№…зұ»еӣҫе‘ўпјҹ
йҰ–е…ҲзңӢListenerзұ»пјҢе®ғиҙҹиҙЈзӣ‘еҗ¬гҖҒеҲӣе»әж–°иҝһжҺҘпјҢе…¶е·ҘдҪңжӯҘйӘӨеҰӮдёӢпјҡ
aгҖҒеҲӣе»әsocketеҸҘжҹ„пјҢз»‘е®ҡз«ҜеҸЈпјҢзӣ‘еҗ¬
bгҖҒи°ғз”ЁselectжЈҖжөӢж–°иҝһжҺҘдәӢ件
cгҖҒеҜ№жЈҖжөӢеҲ°зҡ„дәӢ件и°ғз”Ёacceptе»әз«Ӣж–°иҝһжҺҘ
dгҖҒи°ғз”Ёvoid Listener::acceptedMP(MessagingPort*mp)ж–№жі•еӨ„зҗҶж–°иҝһжҺҘпјҢи°ҒйҮҚж–°е®һзҺ°acceptedMPж–№жі•и°ҒеҶіе®ҡеӨ„зҗҶж–№ејҸ
иҝҷдёӘListenerзұ»ж—ўз”ЁдәҺеӨ„зҗҶwebиҜ·жұӮпјҢд№ҹз”ЁдәҺеӨ„зҗҶжҷ®йҖҡзҡ„ж•°жҚ®еә“иҜ·жұӮгҖӮ
OKпјҢзҺ°еңЁжҲ‘们зңӢwebиҜ·жұӮжҳҜеҰӮдҪ•еӨ„зҗҶзҡ„гҖӮMiniWebServerзұ»з»§жүҝдәҶListenerзұ»пјҢе®ғйҮҚж–°е®һзҺ°дәҶacceptedMPж–№жі•пјҢејҖе§ӢжҺҘ收TCPжөҒпјҢи§ЈжһҗHTTPеҚҸи®®пјҢеҗҢж—¶иҝҳдјҡиҙҹиҙЈз»„иЈ…HTTPе“Қеә”еҢ…并еҸ‘йҖҒTCPжөҒеҲ°е®ўжҲ·з«ҜгҖӮйӮЈд№Ҳе®һйҷ…е®ҢжҲҗhttpиҜ·жұӮзҡ„зұ»жҳҜи°Ғе‘ўпјҹе®ғжҳҜ继жүҝдәҶMiniWebServerзұ»зҡ„DbWebServerзұ»гҖӮиҝҷдёӘзұ»йҮҚж–°е®һзҺ°дәҶdoRequestж–№жі•пјҢе®ғдјҡеңЁе®Ңж•ҙжҺҘ收еҲ°HTTPиҜ·жұӮеҗҺиў«и°ғз”ЁпјҢHTTPиҜ·жұӮзҡ„еӨ„зҗҶиҝҮзЁӢдёҚеңЁжң¬зҜҮзҡ„и®Ёи®әиҢғеӣҙеҶ…пјҢиҝҷйҮҢз•ҘиҝҮгҖӮдҪҶжҲ‘们清жҘҡдәҶпјҢиҝҷдёӘзәҝзЁӢйҮҮз”ЁеҗҢжӯҘзҡ„йҳ»еЎһзҡ„ж–№ејҸеӨ„зҗҶиҜ·жұӮпјҢе®ғж„Ҹе‘ізқҖе®ғеҗҢдёҖж—¶еҲ»еҸӘиғҪеӨ„зҗҶдёҖдёӘwebиҜ·жұӮпјҢ并еҸ‘иғҪеҠӣи¶…зә§ејұпјҢиҝҳеҘҪwebиҜ·жұӮеҸӘжҳҜmongodзҡ„еүҜдёҡпјҢд»…з”ЁдәҺжҹҘиҜўзҠ¶жҖҒгҖӮ
6гҖҒдё»зӣ‘еҗ¬зәҝзЁӢе’Ңж•°жҚ®иҜ·жұӮзҡ„еӨ„зҗҶзәҝзЁӢ
еӨ„зҗҶж•°жҚ®еә“иҜ·жұӮзҡ„жҳҜдёҠеӣҫдёӯзҡ„PortMessageServer зұ»пјҢе®ғиҝҗиЎҢеңЁдё»зәҝзЁӢдёӯгҖӮ
жҲ‘们е…ҲзңӢзңӢPortMessageServer зұ»жҳҜеҰӮдҪ•е®һзҺ°acceptedMPж–№жі•зҡ„пјҡ
virtual voidacceptedMP(MessagingPort * p) {
if ( !connTicketHolder.tryAcquire() ) {
sleepmillis(2); // otherwisewe'll hard loop
return;
}
вҖҰ
int failed =pthread_create(&thread, &attrs, (void*(*)(void*)) &pms::threadRun,p);
вҖҰ
}
еҫҲжё…жҷ°пјҢе®ғејҖеҗҜдәҶдёҖдёӘзәҝзЁӢзӢ¬з«Ӣзҡ„жү§иЎҢиҝҷдёӘиҜ·жұӮгҖӮиҷҪ然иҝҷз§Қж–№ејҸдҫқ然жҖ§иғҪжһҒе·®пјҡеӨ§йҮҸзҡ„иҝӣзЁӢй—ҙдёҠдёӢж–ҮеҲҮжҚўеңЁзӯүзқҖжҲ‘们пјҢдҪҶжҖ»жҜ”webиҜ·жұӮеӨ„зҗҶиҰҒеҘҪеӨҡдәҶпјҢиҖҢдё”mongodзҡ„并еҸ‘иғҪеҠӣжң¬жқҘе°ұдёҚжҳҜе®ғзҡ„й•ҝйЎ№гҖӮ
еҜ№дәҺжҜҸдёӘж–°иҝһжҺҘпјҢйғҪдјҡжңүзұ»е°ҒиЈ…жҲҗеҜ№иұЎпјҢеҰӮдёӢпјҡ
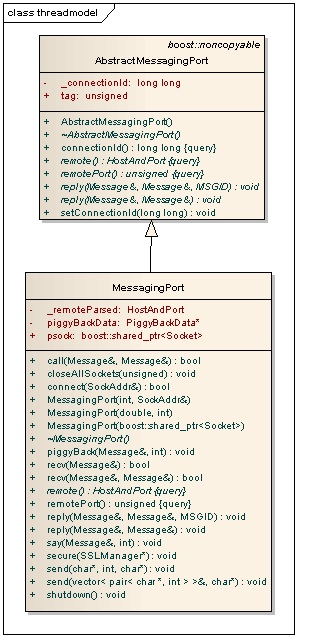
жҺҘдёӢжқҘpms::threadRunж–№жі•жҳҜеңЁеӨ„зҗҶMessagingPortеҜ№иұЎгҖӮ
дёӢйқўзңӢзңӢpms::threadRunж–№жі•дёӯеҒҡдәҶдәӣд»Җд№Ҳпјҡ
void threadRun( MessagingPort *inPort) {
TicketHolderReleaserconnTicketReleaser( &connTicketHolder );
Message m;
try {
LastError * le = newLastError();
lastError.reset( le ); //lastError now has ownership
handler->connected( p.get());
while ( ! inShutdown() ) {
if ( ! p->recv(m) ) {
p->shutdown();
break;
}
handler->process( m ,p.get() , le );
}
}
handler->disconnected( p.get());
}
еҸҜд»ҘзңӢеҲ°пјҢе®ғдјҡеңЁиҝҷдёӘиҝһжҺҘдёҠжҺҘ收е®Ңж•ҙзҡ„иҜ·жұӮпјҢд№ӢеҗҺдјҡи°ғз”Ёhandlerзҡ„processж–№жі•гҖӮиҝҷдёӘhandlerеҸҲжҳҜд»Җд№Ҳе‘ўпјҹеҰӮдёӢеӣҫжүҖзӨәпјҡ

жүҖд»ҘпјҢжҷ®йҖҡзҡ„ж•°жҚ®еә“иҜ·жұӮжҳҜз”ұMyMessageHandlerзҡ„processж–№жі•еӨ„зҗҶзҡ„гҖӮиҝҷдёӘж–№жі•йҮҢд№ҹеҸӘжҳҜдёӘе°ҒиЈ…пјҢзңҹжӯЈеӨ„зҗҶдёҡеҠЎзҡ„жҳҜе…ЁеұҖж–№жі•assembleResponseгҖӮ
assembleResponseж–№жі•дёӯдјҡжҢүз…§8з§Қж“ҚдҪңж–№ејҸеҲҶеҲ«зҡ„и°ғз”ЁDataFileMgrдёӯзҡ„ж–№жі•еӨ„зҗҶе®һйҷ…ж–Ү件пјҢдҫӢеҰӮпјҡ
enum Operations {
opReply = 1, /* reply. responseTo is set. */
dbMsg = 1000, /* generic msg command followed by a string */
dbUpdate = 2001, /* update object */
dbInsert = 2002,
//dbGetByOID = 2003,
dbQuery = 2004,
dbGetMore = 2005,
dbDelete = 2006,
dbKillCursors = 2007
};
еңЁж–№жі•дёӯжңүзұ»дјјиҝҷж ·зҡ„д»Јз ҒеңЁи°ғз”Ёе®һйҷ…зҡ„дёҡеҠЎзұ»еӨ„зҗҶж“ҚдҪңпјҡ
else if ( op == dbInsert ) {
receivedInsert(m, currentOp);
}
else if ( op == dbUpdate ) {
receivedUpdate(m, currentOp);
}
else if ( op == dbDelete ) {
receivedDelete(m, currentOp);
}
еҪ“然жң¬зҜҮеҝ—дёҚеңЁжӯӨпјҢдёӢзҜҮжҲ‘们еҶҚи®Ёи®әзҙўеј•е’Ңж•°жҚ®ж–Ү件зҡ„ж“ҚдҪңгҖӮ
еҲҶдә«еҲ°пјҡ




зӣёе…іжҺЁиҚҗ
MybatisжЎҶжһ¶---->springжЎҶжһ¶---->springmvcжЎҶжһ¶--->ssmдёүеӨ§жЎҶжһ¶ж•ҙеҗҲ--->maven--->SVN/GIT--->hibernateжЎҶжһ¶--->struts2жЎҶжһ¶--->linux--->SSMйЎ№зӣ®з»јеҗҲе°Ҹз»ғд№ --->SpringBoot--->...
socketйҖҡдҝЎе®һзҺ°,зҷ»еҪ•зі»з»ҹ,зҺ©е®¶зәҝзЁӢжЁЎеһӢ,dbзі»з»ҹ,еҲҶеёғејҸidз”ҹжҲҗеҷЁ,еҲҶеёғејҸй”Ғ,зј“еӯҳзі»з»ҹ,зғӯжӣҙж–°жңәеҲ¶,rpcзі»з»ҹ,е…ЁжңҚз»„йҳҹзӯүзӯүз»„з»Үз»“жһ„gameserverв”ңв”Җв”Җ client -- жөӢиҜ•з”Ёnettyе®ўжҲ·з«Ҝв”ңв”Җв”Җ rpc-api -- жҸҗдҫӣеҲҶеёғејҸзҡ„rpcеҹәзЎҖв”ң...
1гҖҒеҹәдәҺз”ЁжҲ·з”»еғҸзҡ„з”өеҪұжҺЁиҚҗзі»з»ҹпјҢд»ҘDjangoдёәеҹәзЎҖжЎҶжһ¶пјҢMTVжЁЎејҸпјҢж•°жҚ®еә“з”ЁMongoDBгҖҒMySQLпјҢеҗ«жәҗз Ғ+дҪҝз”ЁиҜҙжҳҺпјҲжҜ•и®ҫпјү.zip 2гҖҒиҜҘиө„жәҗеҢ…жӢ¬йЎ№зӣ®зҡ„е…ЁйғЁжәҗз ҒпјҢдёӢиҪҪеҸҜд»ҘзӣҙжҺҘдҪҝз”ЁпјҒ 3гҖҒжң¬йЎ№зӣ®йҖӮеҗҲдҪңдёәи®Ўз®—жңәгҖҒж•°еӯҰгҖҒз”өеӯҗдҝЎжҒҜ...
4.1.1 жҜ”иҫғдәӢ件еӣһи°ғе’ҢзәҝзЁӢжЁЎеһӢ 51 4.1.2 еңЁNode.jsдёӯйҳ»еЎһI/O 52 4.1.3 дјҡиҜқзӨәдҫӢ 54 4.2 е°Ҷе·ҘдҪңж·»еҠ еҲ°дәӢ件йҳҹеҲ— 54 4.2.1 е®һзҺ°е®ҡж—¶еҷЁ 55 4.2.2 дҪҝз”ЁnextTickжқҘи°ғеәҰе·ҘдҪң 58 4.2.3 е®һзҺ°дәӢ件еҸ‘е°„еҷЁе’Ңзӣ‘еҗ¬еҷЁ 59 4.3 е®һзҺ°еӣһ...
е°ҒиЈ…дәҶж¶ҲжҒҜйҳҹеҲ—гҖҒзәҝзЁӢжЁЎеһӢгҖҒеҸҠеҜјиЎЁзӯүеёёз”Ёе·Ҙе…·зұ»гҖӮзҪ‘е…іжңҚеҠЎеҷЁдҪҝз”Ёminaе°ҒиЈ…дәҶTCPгҖҒUDPгҖҒWebSocketгҖҒHTTPйҖҡдҝЎпјҢдҪҝиҜҘжЎҶжһ¶иғҪеҗҢж—¶ж”ҜжҢҒеӨҡз§ҚеҚҸи®®зҡ„е®ўжҲ·з«ҜиҝӣиЎҢжёёжҲҸгҖӮжҜҸдёӘд»ҘscriptsеҗҚеӯ—з»“е°ҫзҡ„зӣ®еҪ•йғҪдёәзӣёеә”йЎ№зӣ®зҡ„и„ҡжң¬ж–Ү件гҖӮ
дёҖдёӘgeccoзҲ¬иҷ«жЎҶжһ¶пјҢз®ҖеҚ•жҳ“з”ЁпјҢдҪҝз”ЁjqueryйЈҺж јзҡ„йҖүжӢ©еҷЁжҠҪеҸ–е…ғзҙ ж”ҜжҢҒзҲ¬еҸ–规еҲҷзҡ„еҠЁжҖҒй…ҚзҪ®е’ҢеҠ иҪҪ ж”ҜжҢҒйЎөйқўдёӯзҡ„ејӮжӯҘajaxиҜ·жұӮ ж”ҜжҢҒйЎөйқўдёӯзҡ„javascriptеҸҳйҮҸжҠҪеҸ– еҲ©з”ЁRedisе®һзҺ°еҲҶеёғејҸ...еҚҒгҖҒGeccoзҲ¬иҷ«жЎҶжһ¶зҡ„зәҝзЁӢе’ҢйҳҹеҲ—жЁЎеһӢ
第 23 з« python е®һзҺ° select е’Ң epoll жЁЎеһӢ socket зҪ‘з»ңзј–зЁӢ 第 24 з« еҜ№ Python-memcache еҲҶеёғејҸж•ЈеҲ—е’Ңи°ғз”Ёзҡ„е®һзҺ° 第 25 з« Parallel Python е®һзҺ°зЁӢеәҸзҡ„并иЎҢеӨҡ cpu еӨҡж ёеҲ©з”ЁгҖҗpp жЁЎеқ—гҖ‘ 第 26 з« е…ідәҺ python ...
в”Ӯ 第80иҠӮпјҡеӨҡзәҝзЁӢconsumerи®ҝй—®йӣҶзҫӨ.avi в”Ӯ 第81иҠӮпјҡйӣҶзҫӨдёӢзҡ„ж¶ҲжҒҜеӣһжөҒеҠҹиғҪ.avi в”Ӯ 第82иҠӮпјҡе®№й”ҷзҡ„й“ҫжҺҘе’ҢеҠЁжҖҒзҪ‘з»ңиҝһжҺҘ.avi в”Ӯ 第83иҠӮпјҡActiveMQзҡ„йӣҶзҫӨ.avi в”Ӯ 第84иҠӮпјҡDestinationй«ҳзә§зү№жҖ§дёҖ.avi в”Ӯ 第85иҠӮпјҡ...
16 27йҒ“йЎ¶е°–зҡ„JavaеӨҡзәҝзЁӢгҖҒй”ҒгҖҒеҶ…еӯҳжЁЎеһӢйқўиҜ•йўҳпјҒ.pdf 17 29йҒ“еёёи§Ғзҡ„SpringйқўиҜ•йўҳпјҒ.pdf 18 30дёӘJavaз»Ҹе…ёзҡ„йӣҶеҗҲйқўиҜ•йўҳпјҒ.pdf 19 36йҒ“йқўиҜ•еёёй—®зҡ„MyBatisйқўиҜ•йўҳпјҒ.pdf 20 40йҒ“еёёй—®зҡ„JavaеӨҡзәҝзЁӢйқўиҜ•йўҳпјҒ.pdf 21 55йҒ“BAT...
е°ҒиЈ…дәҶж¶ҲжҒҜжЁЎеһӢпјҢзәҝзЁӢжЁЎеһӢпјҢд»ҘеҸҠеҜјиЎЁзӯүеёёз”Ёе·Ҙе…·зұ»гҖӮзҪ‘е…іжңҚеҠЎеҷЁдҪҝз”Ёminaе°ҒиЈ…дәҶTCPпјҢUDPпјҢWebSocketпјҢHTTPйҖҡдҝЎпјҢдҪҝиҜҘжЎҶжһ¶иғҪеҗҢж—¶ж”ҜжҢҒеӨҡз§ҚеҚҸи®®зҡ„е®ўжҲ·з«ҜиҝӣиЎҢжёёжҲҸгҖӮжҜҸдёӘд»Ҙи„ҡжң¬еҗҚз§°ејҖеӨҙзҡ„зӣ®еҪ•йғҪдёәзӣёеә”йЎ№зӣ®зҡ„и„ҡжң¬ж–Ү件гҖӮж–Ү件...
node.jsжҳҜд»Җд№Ҳ ... ејҖеҸ‘е№іеҸ°жҳҜжҢҮпјҢжңүеҜ№еә”зҡ„зј–зЁӢиҜӯиЁҖпјҢжңүиҜӯиЁҖиҝҗиЎҢж—¶пјҢжңүиғҪе®һзҺ°зү№е®ҡеҠҹиғҪAPIпјҲSDKпјҡSoftware Development Kitпјү иҜҘе№іеҸ°дҪҝз”Ёзҡ„зј–зЁӢиҜӯиЁҖжҳҜJavaScript...йқһйҳ»еЎһ I/O жЁЎеһӢпјҲеҪ“жү§иЎҢI/Oж“ҚдҪңж—¶пјҢдёҚдјҡйҳ»еЎһзәҝзЁӢпјү еҚ•зәҝ
ејҖеҸ‘е·Ҙе…·еҸҠзүҲжң¬:CubeMX v6.1.0гҖҒKeil v5.33гҖҒVSCode v1.51.1гҖҒAndroid Studio 4.1.1гҖҒHBuilder X v2.9.8.20201110гҖҒNodeJS v14.15.1гҖҒMongoDB v4.4.1(1дё»2еүҜ)гҖҒredis v6.0 RT-ThreadдҪҝз”Ёжғ…еҶөжҰӮиҝ°еҶ…ж ёйғЁеҲҶ:и°ғеәҰеҷЁгҖӮ ...
mongodb hadoop дёҡеҠЎжӢҶеҲҶ web service restful еҲҶеёғејҸжңҚеҠЎ еӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҢ–зҡ„д»·еҖји§Ӯ ж ёеҝғд»·еҖјпјҡйҡҸзҪ‘з«ҷжүҖйңҖзҒөжҙ»еә”еҜ№ й©ұеҠЁеҠӣйҮҸпјҡзҪ‘з«ҷзҡ„дёҡеҠЎеҸ‘еұ• зҪ‘з«ҷжһ¶жһ„и®ҫи®ЎиҜҜеҢә дёҖе‘іиҝҪйҡҸеӨ§е…¬еҸёзҡ„и§ЈеҶі...